Content Analysis Terminology:
Understanding Wording Differences across Fields
Content analysis, a versatile method to systematically and qualitatively analyze text, image, and audio data, serves the purpose of extracting valuable insights, find important information and discover repeated patterns or main ideas. However, the context-dependent terminology used in content analysis can sometimes be confusing: Different researchers and fields may use different terms to refer to the same or similar concepts. Therefore, this post aims to define the key terminology we use in textada and how they relate to terms used in other contexts.

What can you do with textada?
Well, content analysis! However, this term and many synonyms describe a set of methods for a variety of media types and a full research pipeline. In textada, you can do one specific part of content analysis: Annotating texts. Qualitative text annotation is a systematic process of analyzing and adding interpretive labels to text spans. When having a large number of annotations, researchers can quantify and aggregate their categories over their data, making it easier to identify patterns, trends, or nuances. This is especially easy with textada since the AI assistant will label all remaining text after adding only a few manual annotations.
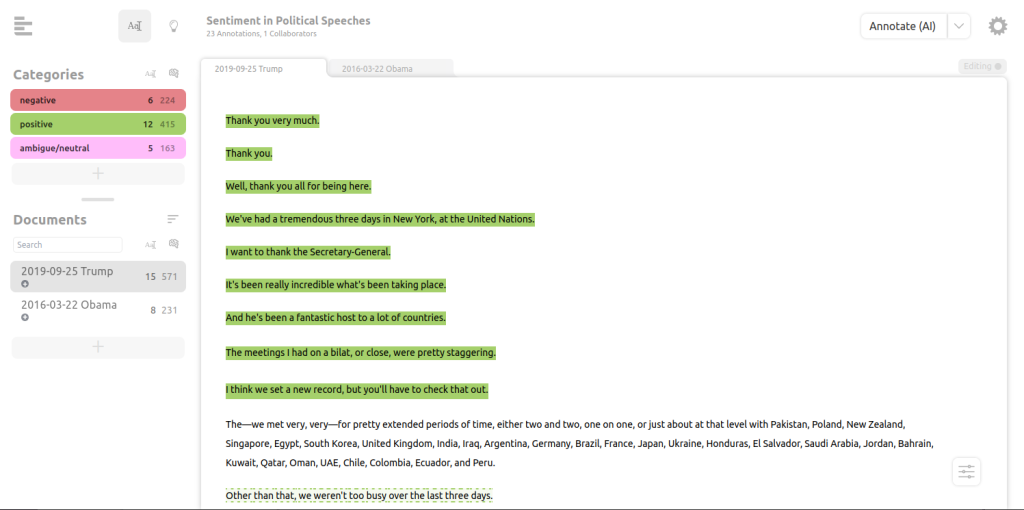
- content analysis / media analysis
Used when analyzing various forms of media content, including text, images, audio, and video. Synonyms are: media analysis - text analysis / document analysis
A subgroup of content analysis that focuses specifically on analyzing written or textual content. This includes the content analysis as done with textada as well as other forms of analysis, such as topic modeling or extracting keywords. - communication analysis / discourse analysis
Focuses on the structure and meaning of spoken or written communication within specific contexts. In general, communication can include different media types than text. In textada, is it is only one of many usecases. - text annotation / text labeling / text coding
Annotation is the method of assigning a set of predefined categories to parts of the text. - text mining
The term text mining originates from computer science. It describes fully automated techniques to extract information and patterns from large volumes of textual data. In textada however, we combine automated methods manual annotation and full control for the user.
What’s the difference between qualitative and quantitative content analysis?
With textada, we follow Philipp Mayring’s approach to content analysis and believe in the strength of combining qualitative and quantitative elements.
- inductive and deductive
In some cases, the qualitative vs. quantitative differentiation refers to inductive vs. deductive content analysis. In inductive analysis, the goal is to follow the data-inherent themes to generate hypotheses about and categories for the data. Deductive annotation aims to find all occurrences of predefined categories in the data. In a next research step, aggregated counts can be the foundation to statistically test hypotheses. textada’s AI assistant deductively annotates your text based on only few manual examples. This makes a statistical analysis of the results easy. But we give you as the user full control: You can always change the category system and the annotations during the process and let the AI assistant update its annotations. - qualitative vs. quantitative text features
In other cases, qualitative content analysis highlights the interpretative and semantic-dependent nature of the analysis process whereas quantitative analysis focuses on word counts or other statistical text features. You can have both in textada but we focus on quality: First, you can use the keyword assistant to quantitatively kickstart your annotation with some class-specific words. But in general, we want you to be able to focus on only few high-quality manual annotations. Therefore, our AI assistant can replicate your qualitative annotation behavior. It can even handle semantic similarity and synonyms, no need to rely on word counts only!
What are we analyzing?
Text! This text is written in documents. The document origin is irrelevant. They may be transcripts, news articles, social media posts or anything else relevant to your task.
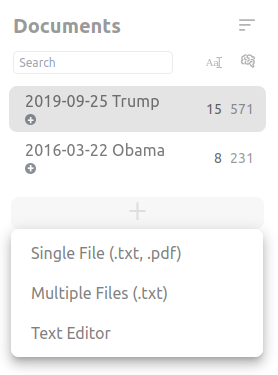
- data / dataset /corpus
The entire collection of your documents - analysis unit
The text chunks you are evaluating for annotation, can – in theory – be arbitrary spans of text. In textada, you can annotate entire documents, paragraphs, sentences or arbitrary sequences. However, the AI assistant will work on the sentence level. This text unit is the analysis unit or coding unit. - file types
What you can load into textada. For single files, you can use text from text files or extract text from PDF files. As a simple rule of thumb: The simpler the formatting, the better the extraction. To load entire projects, you can use the QDPX format. Although this format can include many data types, you can only work with the text documents.
What do we find in the text?
In textada, you can define categories, which are concepts you define that you want to look for in your data. These categories can be different topics, sentiments, political stances or anything else.
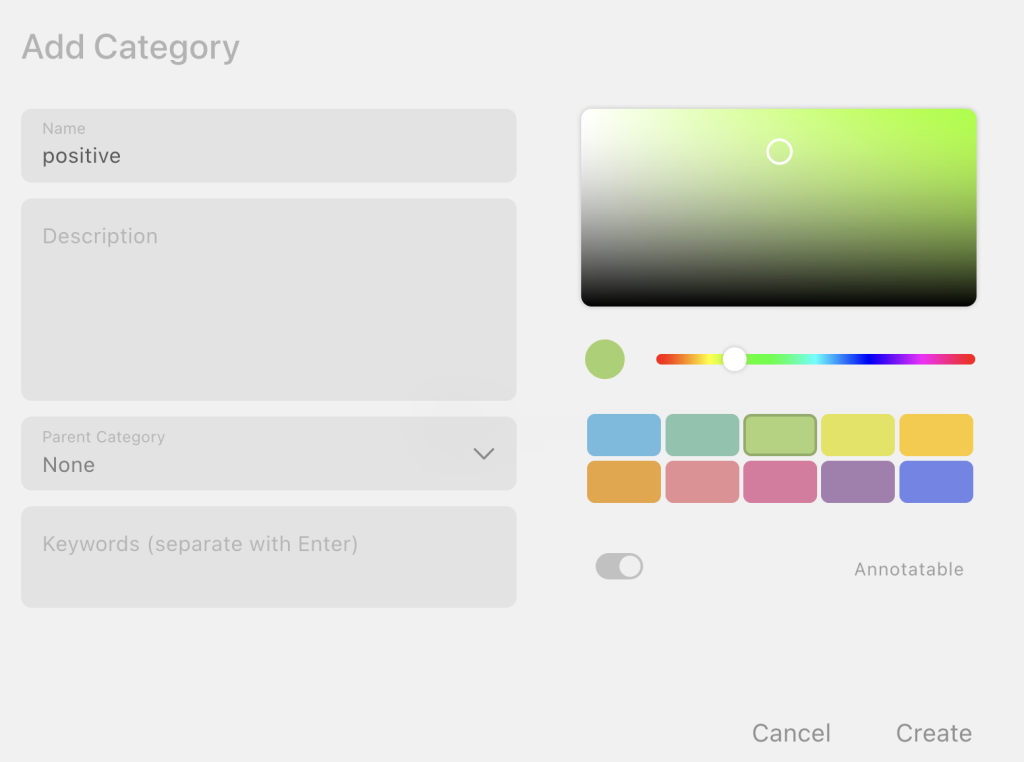
- categories / labels/ codes / classes
In textada, these terms are synonyms and all refer to the same concept. In computer science, label often refers to the name of a category or the category value for one text. - annotation
An annotation is a span of text that has been assigned a category. When this annotation has been made by textada’s AI assistant or keyword assistant and needs to be confirmed by the human expert, it is also called a suggestion or prediction.
Which terminology should I use?
In conclusion, remember that the terminology surrounding content analysis is diverse. The same concept can have various names depending on the field and researcher. While this diversity exists, the fundamental process remains consistent: systematically analyzing content to extract meaning and patterns. Ultimately, the choice of terminology is flexible and context-dependent. This allows you to select the terminology that best suits your research objectives and the conventions within your field. We hope that whatever terminology you choose, you are now aware of the term used in textada for that concept.
We hope this post helped to clarify all uncertainties about the wording in research theory, previously used software and textada. You can start your textada project right away by getting your free access or you can check out our quick start tutorial!